Transformer를 가장 쉽게 설명한 글 1탄
아래의 글은 Jinsol Kim 님의 블로그 글을 보고 정리한 글입니다.
참조: https://gaussian37.github.io/dl-concept-transformer/
참조: https://jalammar.github.io/illustrated-transformer/
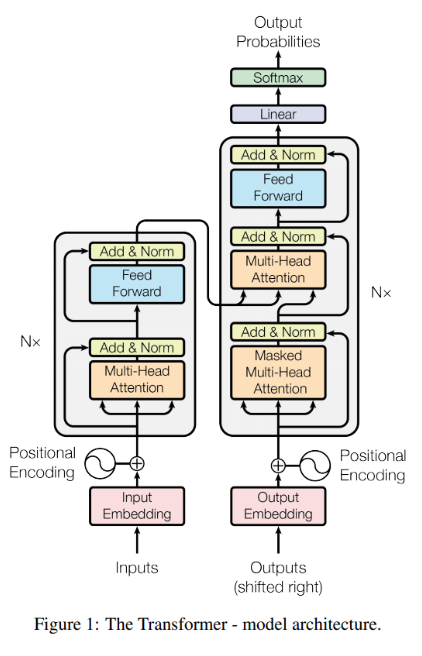
1. Transformer 특징
- 번역 task에서 RNN과 CNN을 쓰지 않고
Attention과Fully Connected Layer와 같은 기본 연산만을 이용하여 SOTA 성능을 이끌어낸 연구로 유명 - (기존 연구의 문제점):
- 하나의 문맥 벡터에 문장의 모든 정보를 함축시켜야 하기 때문에 성능이 저하
- (해결 방안):
- 모델이 학습될 때마다 문장의 전부를 입력으로 받으면 어떨까? → 하나의 벡터에 저장하지 말고 출력된 단어들을 별도의 배열에 저장했다가 출력될 때 이 배열 또한 반영!
- 좀 더 자세히 말하면 이러한 출력값들을 반영한 weigt 값을 통해 출력에 반영하겠다
- 모델이 학습될 때마다 문장의 전부를 입력으로 받으면 어떨까? → 하나의 벡터에 저장하지 말고 출력된 단어들을 별도의 배열에 저장했다가 출력될 때 이 배열 또한 반영!
Seq2seq와 유사한Encoder - Decoder형식 사용Scaled Dot-Product Attention과 이를 병렬로 연결한Multi-Head Attention이 알고리즘의 핵심- RNN →
BPTT(Back Propagation Through Time) 구조로 인해 시간이 흐르는 기준으로 펼쳐놓고 봐야 하기 때문에 순차적인 연산 필요: 연산 효율이 떨어진다 - Transformer → BPTT와 같은 구조가 없고 병렬 계산이 가능: 효율적인 연산 가능
- Transformer → RNN과 다르게 병렬적으로 계산 가능하기 때문에 “현재 계산하고 있는 단어가 어느 위치에 있는 단어인지를 표현해 주어야 한다” (seq2seq처럼 input으로 word가 순서대로 들어가는 것이 아니기 때문에 순서 정보를 별도로 담기 위해): Positional Embedding 사용 이유
2. Transformer, seq2seq 차이
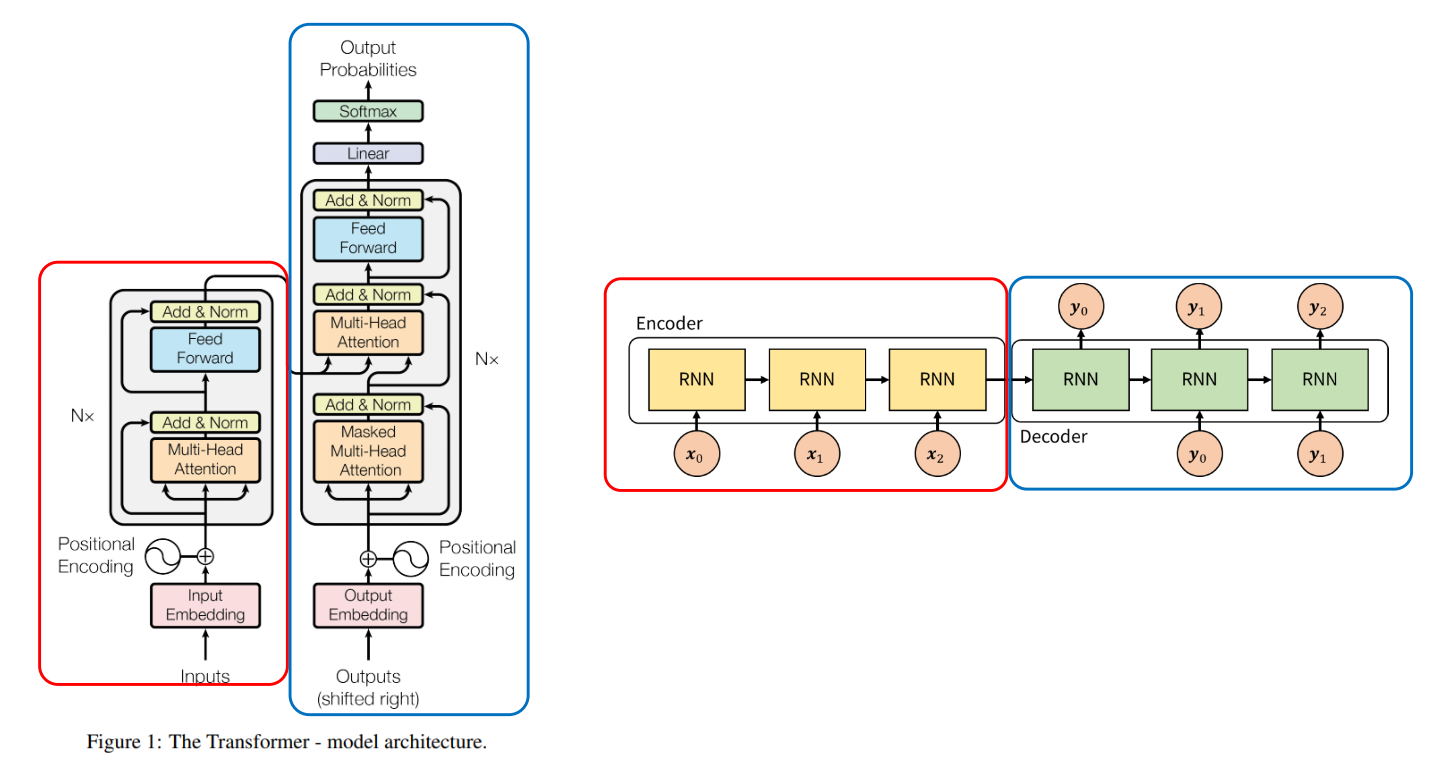
Seq2seq: Encoder와 Decoder에는 RNN 사용 & Encoder에서 Decoder로 정보를 전달할 때, 가운데 화살표인 context vector에 Encoder의 모든 정보를 저장하여 Decoder로 전달Transformer: Encoder 끝단 부분에 Decoder로 전달
💡 seq2seq에서는 Encoder에 입력되어야 할 **모든 input이 처리된 후에 Decoder 연산이 시작, Transformer →Encoder와 Decoder의 계산이 동시에 일어남**
3. Transformer input, output
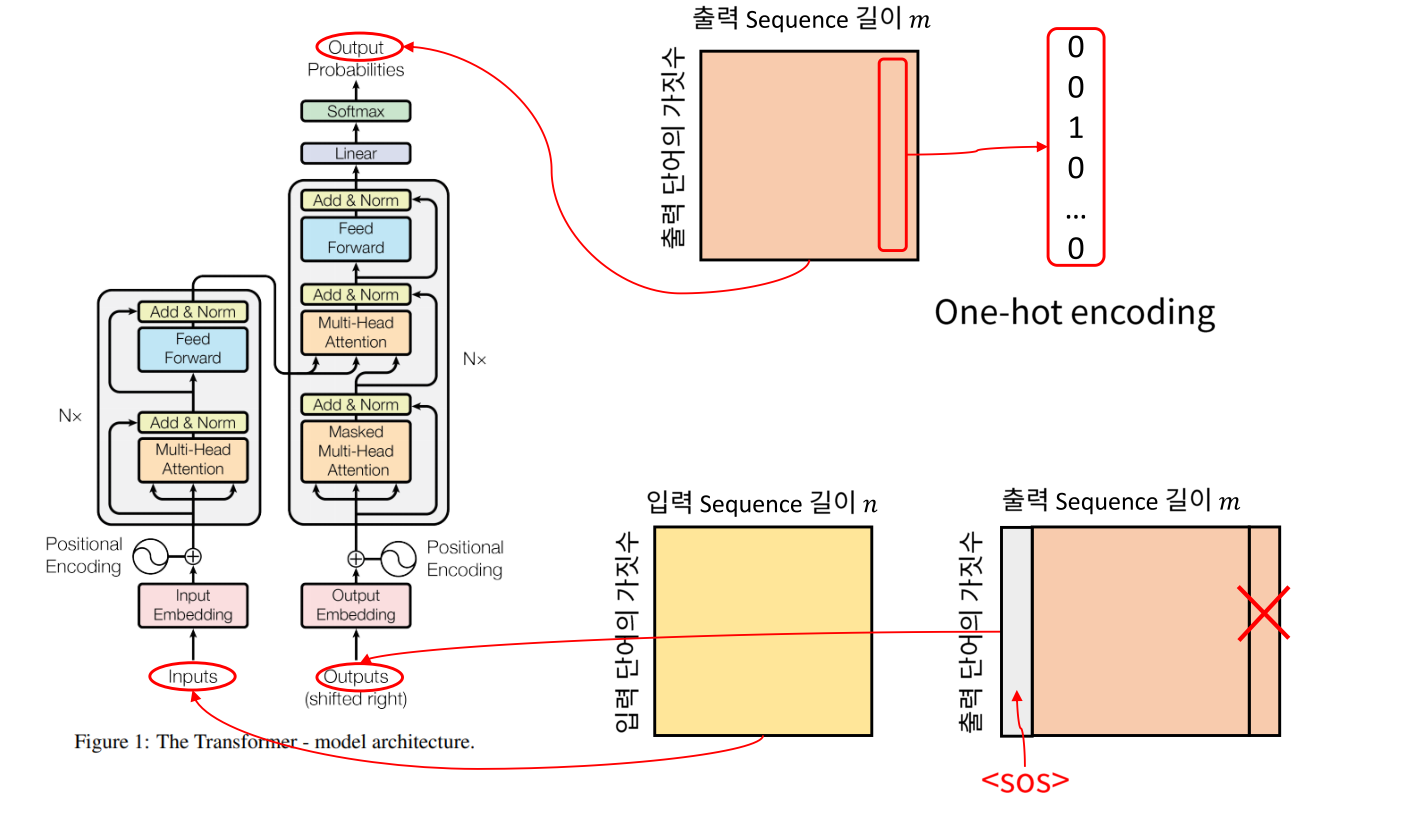
- Transformer 모델이 자연어 번역을 위해 개발되었기 때문에 전체 입출력 형태는 행렬과 같이 보임
Input:각 단어는 One-hot encoding의 벡터로 나타내어짐 → 열 벡터가 한 단어에 해당(행의 길이 = 입력 단어의 가짓수) (열의 크기 = 한 문장에서의 단어의 개수)Output: Transformer가 처음 다룬 문제가 번역이기 때문에 입력이 영어, 출력이 한국어일 경우 단어의 갯수가 달라지는 경우가 있을 수 있음 → (행의 길이 = 출력 단어의 가짓수) (열의 크기 = 한 문장에서 사용된 단어의 개수)- output의 첫 열 벡터는
SOS(Start of Sequence)가 되고 X 표시가 되어있는 마지막 열벡터는EOS(End of Sequence)이므로 큰 의미 없는 벡터
- output의 첫 열 벡터는
4.Transformer Word Emebedding
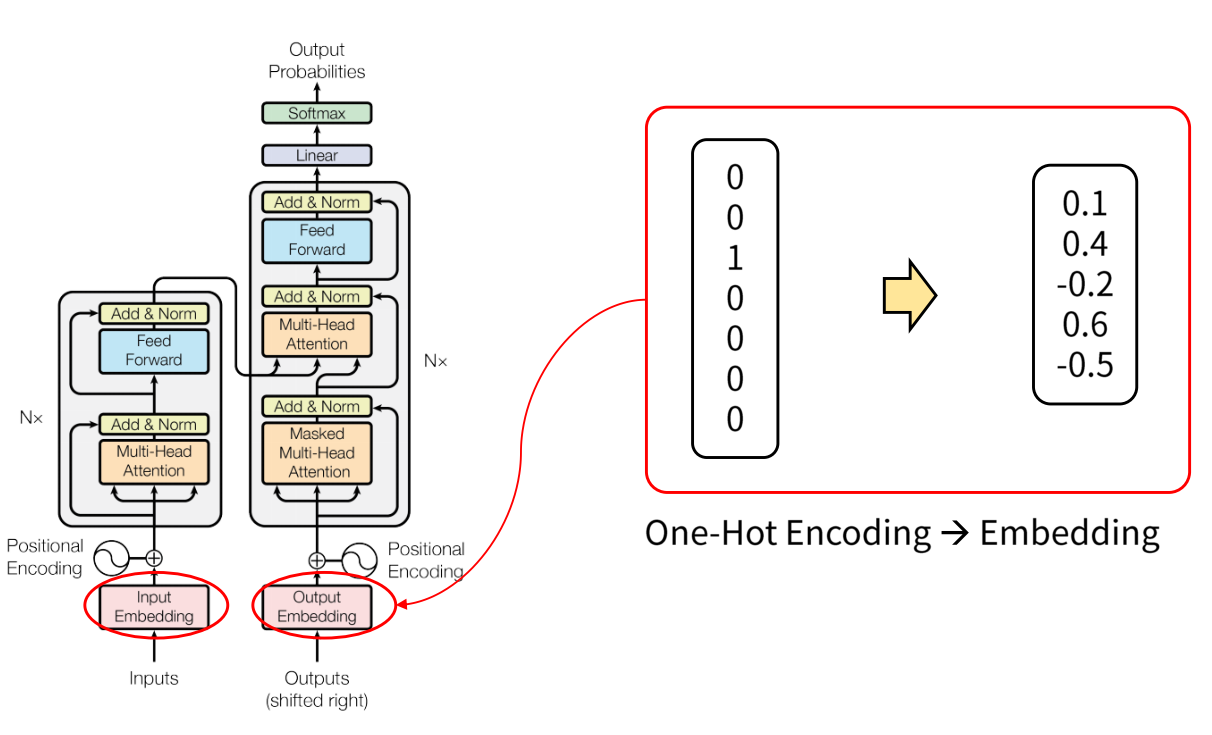
- one-hot encoding 타입의 벡터를 →실수 형태로 변경 : 차원의 수를 줄일 수 있음
4.1 Positional Encoding
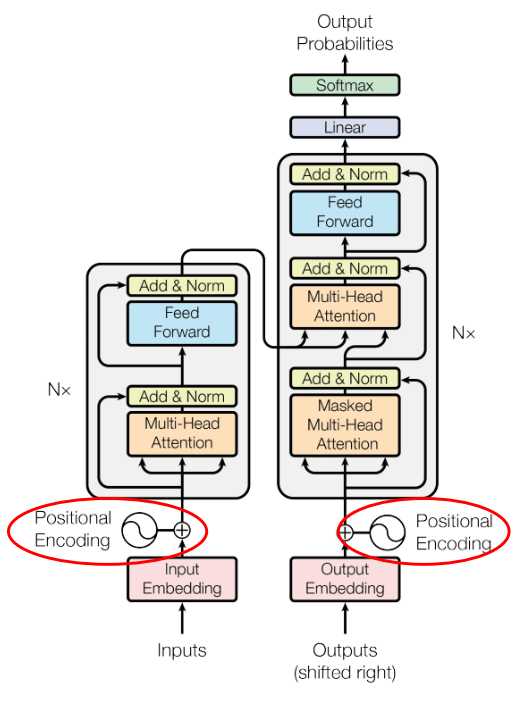
- word embedding을 마친 후에 → Positional encoding을 통해 embedding이 더해짐
- Transformer에서는 차례 차례 입력되지 않기 때문에 Positional Encoding을 통해 시간적 위치 정보를 추가
- Encoding은
sin,cos함수를 통해 생성된 값으로 → 이 주기 함수에 대한 규칙을 모델이 학습을 통하여 배움으로써 입력값의 상대적 위치를 알 수 있게 됨
$$\text{PE}{(\text{pos}, 2i)} = \sin{(\text{pos}/10000^{2i / \text{d}{\text{model}}})}$$
$$\text{PE}{(\text{pos}, 2i+ 1)} = \cos{(\text{pos}/10000^{2i / \text{d}{\text{model}}})}$$
pos→상대적 위치i→벡터의 인덱스- 최근 ⇒ 기존의
sin, cos방식보다는nn.Embedding(max_length, embed_size)와 같은 embedding 방식을 활용하여 학습하는 방식 사용
5. Scaled Dot-Product Attention **
Transformer 핵심: scaled dot-product attention, multi-head attention
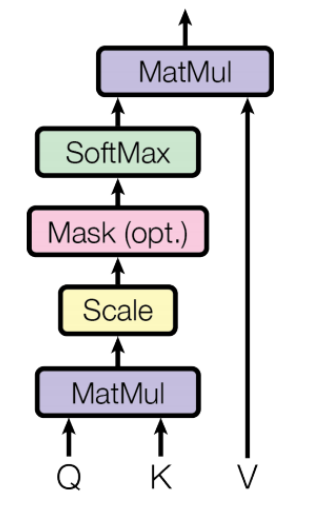
self-attention:각각의 입력이 서로 다른 입력에게 어떤 연관성을 가지고 있는지 구하기 위해 사용(어떤 단어가 다른 단어들과 어떤 연관성을 갖는지 확인)- Q: 물어보는 주체 (e.g. “I am a teacher”에서 I가 어떤 단어와 연관이 있는지 확인할 때의 Q는 “I”가 됨)
- K: 물어보는 대상 (e.g “I”를 제외한 나머지 각각의 단어들)
- V: Q와 어떤 K가 가장 높은 연관성을 갖고 있는지 나타낸(계산된) 확률값(softmax를 지남)을 최종적으로 곱하는 대상 → 이를 통해 weighted 된 matrix를 얻게 됨
- 위의 예시들은 encoder attention의 경우임 // encoder-decoder attention의 경우에서는 다르게 적용될 수 있음
- decoder의 출력을 만들기 위해서 각각의 단어들이 encoder의 어떤 단어들을 참고하면 좋을지 확인하기 위해
- Q: decoder의 출력 단어
- K: encoder를 통해 입력된 각각의 값
- decoder의 출력을 만들기 위해서 각각의 단어들이 encoder의 어떤 단어들을 참고하면 좋을지 확인하기 위해
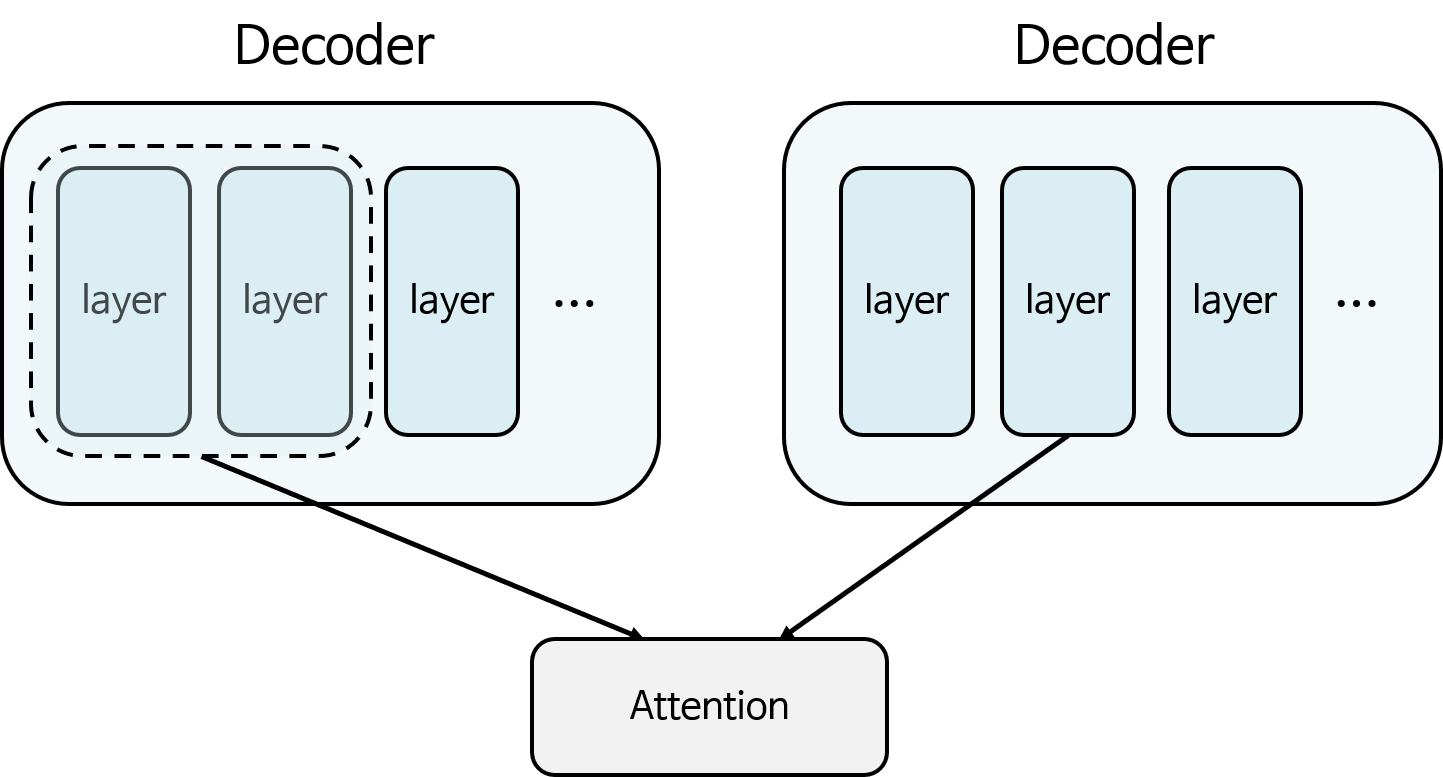
- seq2se2 에 사용된 Attention →Encoder에서 사용된 모든 step 별 layer와 decoder의 특정 layer를 이용하여 Attention 연산 수행
- self Attention →Decoder가 똑같은 Decoder 자신과 Attention 연산 수행 가능 (self-attention을 하기 위해선 어느 특정 layer보다 앞선 layer들만 가지고 attention 수행 가능)
)
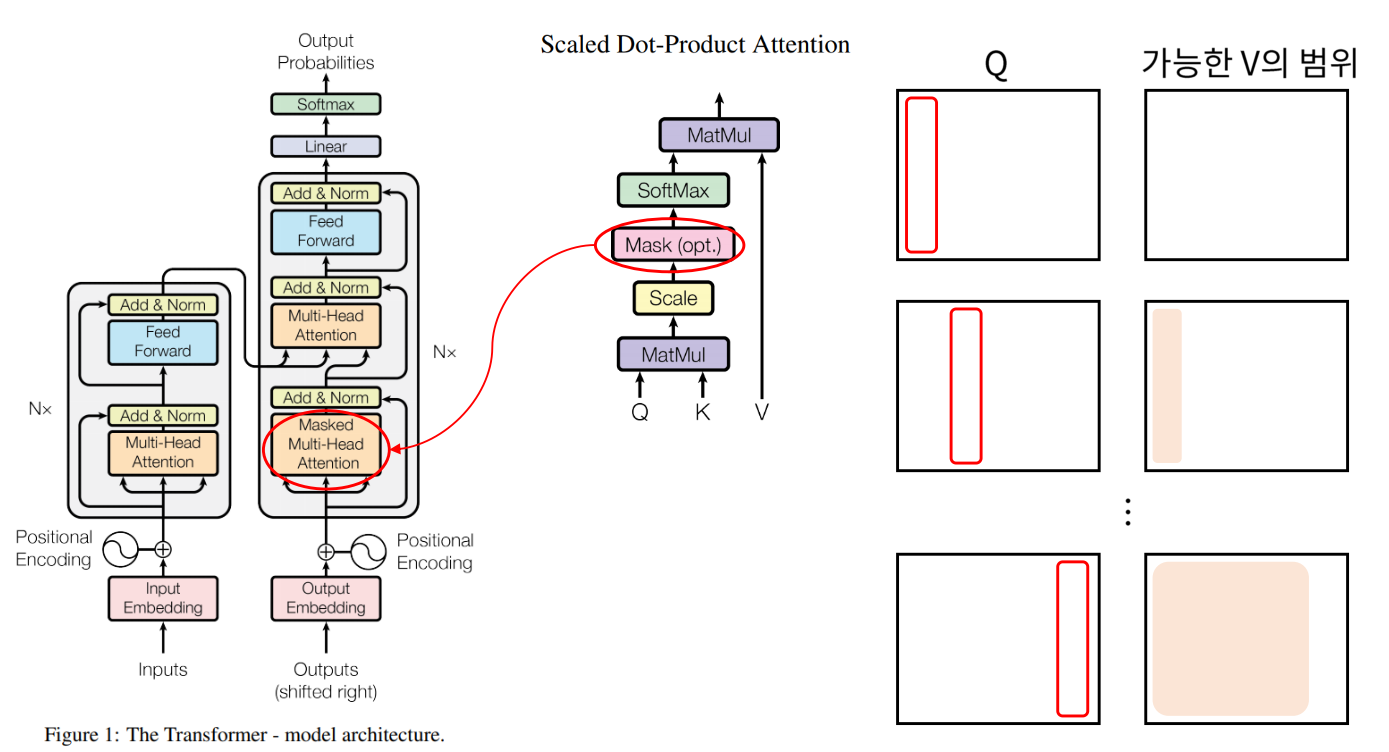
- Q와 가능한 V의 범위를 살펴보면 선택된 Q에 대하여
가능한 V의 범위는 위치상Q의 바로 앞까지임 - 따라서
mask를 이용하여 이러한 illegal connection의 attention을 금지해줌
💡 Self-Attention에서는 **자기 자신을 포함한 미래의 값과는 Attention을 구하지 않기 때문에** Masking 사용
Scaled Dot-Product AttentionOutput- scale(k dimension으로 나누는 이유): softmax 결과가 0에 가깝게 saturation되는 것을 방지
$$C = \text{softmax} \Biggl(\frac{K^{T}Q}{\sqrt{d_{k}}}\Biggr)$$
$$C^TV=softmax(\frac{K^TQ}{√d_k})V=a$$
- 위의 식은 행렬의 곱과 softmax의 형태로만 이루어져 있음: GPU를 이용하여 행렬 곱이 가능하기 때문에 연산 속도가 빠르다는 점이 Transformer의 가장 큰 장점임
6.Multi-Head Attention
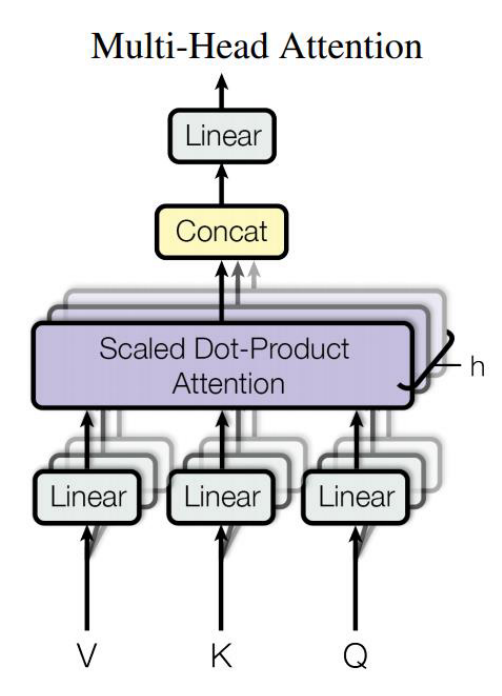
multi-head attention:scaled-dot product attention을h개 모아서 attention layer를 병렬적으로 사용하는 것- scaled dot-product attention에서 몇 개로 분할하여 연살할지 → 각각의 scaled dot-product attention의 입력 크기가 결정
Transformer
- Transformer 특징
- Transformer, seq2seq 차이
- Transformer input, output
- Transformer Word Emebedding
- 1 Positional Encoding
- Scaled Dot-Product Attention **
- Multi-Head Attention
- Position-Wise Feed-Forward
- Softmax & Linear
- 이점: Linear 연산을 통해 Q,K,V의 차원을 감소하는 것은 모델이 어느 특정한 차원들만 선택해서 보겠다는 것을 의미. →차원을 축소해서 보되 병렬적으로 검토 ⇒ 연산 속도 증가 + 다방면으로 모델이 학습 가능
💡 Decoder의 Multi-Head Attention에만 **Mask가 적용 (이유: Key, Value가 Query가 하는 것보다 더 앞서서 등장할 수 없기 때문)**
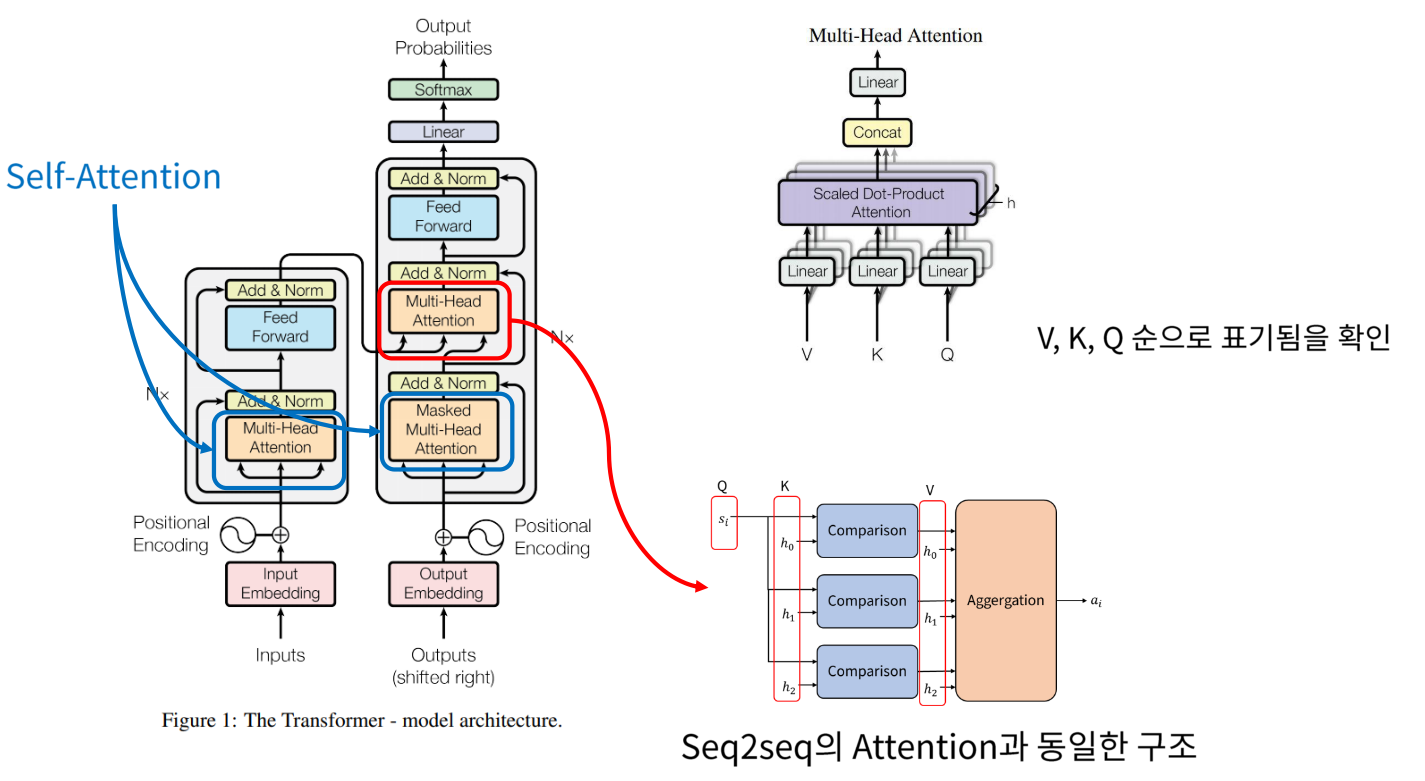
- 파란색 부분 → Self-Attention: attention이 강조되어 있는 feature 추출 가능 (이때의 Q,K,V 차원은 모두 같음)
- 빨간색 부분 →Multi-Head Attention: Encoder로부터 key와 value를 받고 Decoder로부터 Query를 받음
7. Position-Wise Feed-Forward
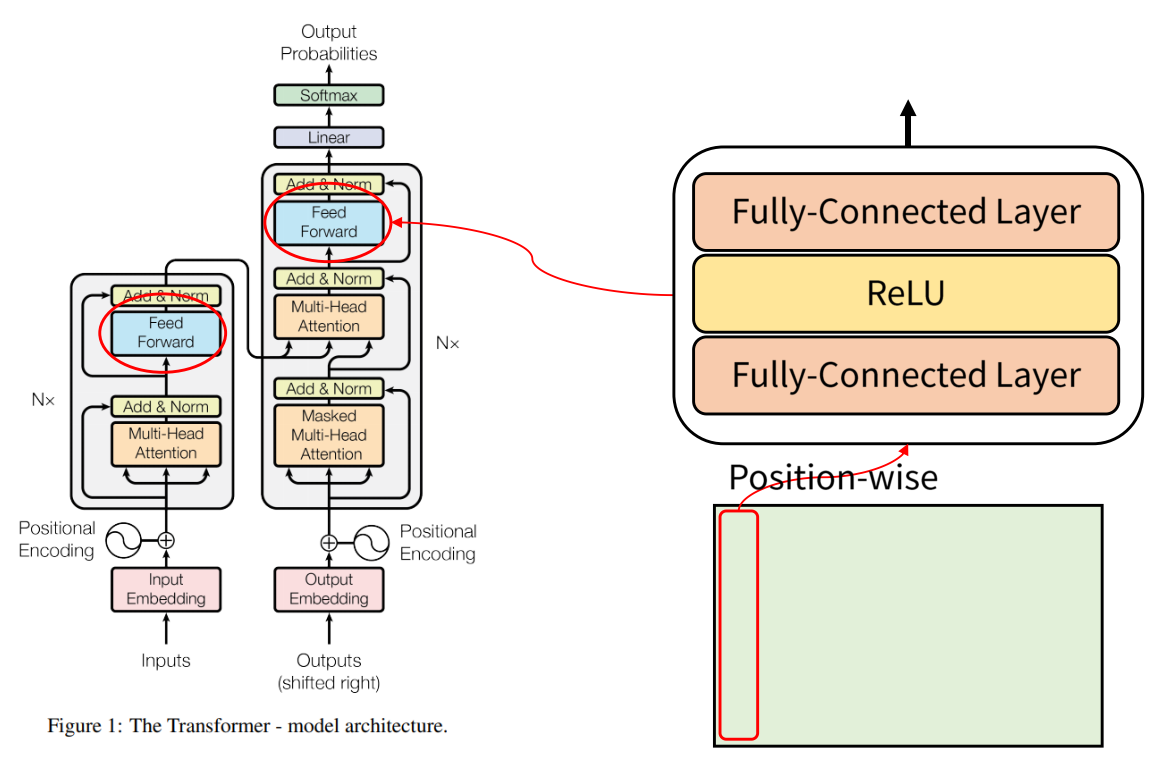
Position-wise Feed-Forward: 단어 position 별로 feed forward한다(=각 단어에 해당하는 열 벡터가 입력으로 들어갔을때FC - Relu - FC를 거친다)
8. Softmax & Linear
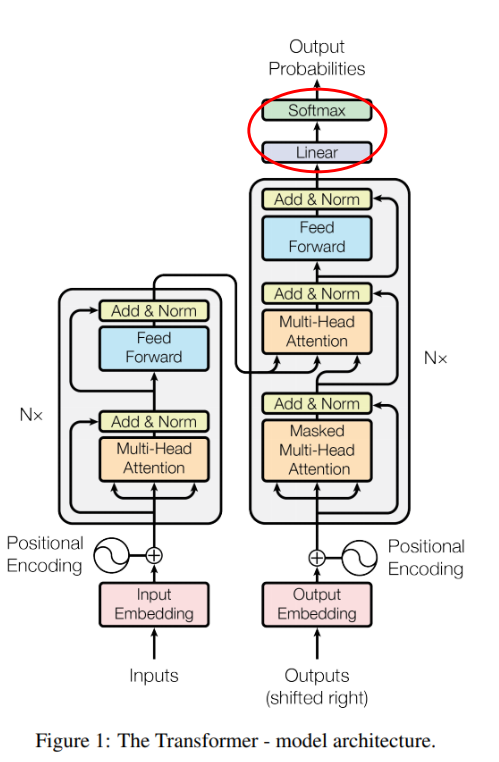
- 마지막으로, Feed Forward를 통해 출력이 되면 Linear 연산을 통해 → 출력 단어 종류의 가짓수로 출력 사이즈를 맞춤
Softmax를 통해 어떤 단어인지 classification 가능